
Да, НЛП – это не только нейролингвистическое программирование. Это еще и natural language processing, что дословно переводится как «обработка естественного языка». Под естественным языком подразумевается тот язык речи, которым мы пользуемся в повседневной жизни для выражения своих мыслей, а под обработкой – способность искусственного интеллекта понимать наш язык таким, какой он есть.
Таким образом, natural language processing – это способность программ, основанных на технологиях искусственного интеллекта, понимать человеческий язык в натуральном виде, так, как пишутся и произносятся фразы и предложения в естественной речи, устной и письменной. Вы всегда будете понимать намного больше, если пройдете нашу программу «Когнитивистика». А наша сегодняшняя тема – NLP: natural language processing (обработка естественного языка).
Natural language processing: немного истории
История NLP ведет свой отсчет с 1954 года, когда был поставлен знаменитый «Джорджтаунский эксперимент». Суть эксперимента вкратце следующая: корпорация IBM совместно с Джорджтаунским университетом публично продемонстрировали, как им совместными усилиями удалось «научить» компьютер переводить тексты с русского языка на английский.
На глазах восторженных зрителей ЭВМ смогла перевести более 60 предложений преимущественно научного содержания, притом, что использовался весьма ограниченный набор из 250 слов. Больше подробностей того поистине судьбоносного эксперимента можно узнать, прочитав пресс-релиз корпорации IBM, вышедший на следующий день [IBM, 1954].
Почему данный эксперимент можно считать судьбоносным? Для того чтобы перевести какое-либо предложение с одного языка на другой, нужно, как минимум, его понять, а чтобы понять что-либо, нужен интеллект. Таким образом, Джорджтаунский эксперимент дал начало эпохе искусственного интеллекта, который способен понимать человеческий зык.
Правда, существуют и альтернативные точки зрения, согласно которым история NLP уходит своими корнями в Средневековье, когда люди впервые задумались о взаимодействии человека и системы символов. Интересующимся можем предложить статью «История обработки естественного языка, с тринадцатого века до наших дней» [Habr, 2019]. Мы же останемся на более традиционных позициях и воздержимся от рассмотрения компьютерных технологий в отсутствие компьютера.
Путь развития технологий машинного перевода, искусственного интеллекта и natural language processing был весьма тернист и полон разочарований как со стороны ученых, так и со стороны структур, потенциально заинтересованных в таких разработках. Тем не менее, на сегодняшний день каждый владелец смартфона может лично убедиться, что гаджет достаточно хорошо понимает своего «хозяина» в отсутствие у хозяина серьезных дефектов дикции и произношения. Поработать над своей дикцией вы можете на нашем бесплатном курсе «Развитие голоса и речи», что будет полезно в общении не только со смартфоном.
Помимо дикции, что важно для понимания сугубо устной речи, имеют значение структура предложения, его построение, правильность согласования падежей, чисел, склонений и прочих составляющих грамматики. Изначально в распоряжении систем искусственного интеллекта и машинного перевода есть только «чистый» язык, без грамматических ошибок и неточностей. А в реальности человеческая речь изобилует и ошибками, и неточностями, и эмоциями, и скрытым смыслом, и неочевидной трактовкой.
Речь не только о классической фразе «казнить нельзя помиловать», где от места постановки запятой полностью меняется смысл. Во многих случаях, даже если просто поменять местами слова в русском языке, смысл меняется тоже. Например, словосочетание «очень умный» несет положительный заряд, а вот в словосочетание «умный очень» обычно вкладывают саркастический, а то и угрожающий смысл.
Как научить машину «обходить» эти препятствия и понимать естественную человеческую речь? Над этим «бились» достаточно долго, и, как мы уже заметили ранее, дело двигалось медленно. Так, в конце 60-х годов 20 века появилась программа для понимания естественного языка SHRDLU, которую разработал профессор информатики из США Терри Аллен Виноград.
По сути, это был синтаксический анализатор языка, позволяющий взаимодействие с пользователем в заданных рамках с ограниченным словарным запасом английского языка. Эти и более поздние разработки Терри Винограда представлены в его работе «Процедуры как представление данных в компьютерной программе для понимания естественного языка» [T. Winograd, 1972].
Далее появилась так называемая ATN (Augmented transition network), что переводится как «расширенная сеть переходов». По замыслу авторов, эта система могла понимать предложение любой степени сложности при условии, что предложение построено грамматически верно. Поэтому основной задачей стало структурирование информации в понятную для «машинного восприятия» форму. Подробности изложены в монографии «Сетевые грамматики перехода для анализа естественного языка» [W. Woods, 1969].
Однако настоящий прорыв произошел, когда появились самообучающиеся системы. Их все можно условно разделить на три группы:
- Контролируемое обучение.
- Неконтролируемое обучение.
- Частично контролируемое обучение.
Если кратко, контролируемое обучение предполагает манипуляции с маркированными данными, неконтролируемое обучение – работу с немаркированными данными, а частично контролируемое предполагает совмещение небольшого объема маркированных данных с большим объемом немаркированных.
По сути, при контролируемом обучении идет сопоставление входных данных с выходными на основе пары из входного объекта и выходного значения. Обработав множество таких данных, машина получает нужные «знания» для того, чтобы правильно понимать человеческую речь. Примером самообучающейся системы может служить программное обеспечение, позволяющее смартфону «понимать» запросы своего хозяина.
Среди наиболее известных разработок в области natural language processing можно назвать следующие:
- Watson (программное обеспечение искусственного интеллекта, разработка корпорации IBM).
- Siri (виртуальный помощник от Apple).
- Google Assistant (виртуальный помощник от Google).
- Amazon Alexa (виртуальный помощник от Amazon).
- «Алиса» (виртуальный помощник от «Яндекс»).
Более полный обзор программных продуктов вы найдете в подборке «ИИ и Natural Language Processing: большой обзор рынка. Часть 2» [Ю. Молодых, 2020]. Так или иначе, большинство из вас уже сталкивалось с различными разработками в области natural language processing и успело оценить как их удобство, так и их несовершенство. Почему же, невзирая на почти 70-летнюю историю разработок в данной области, пока что так и не удалось создать абсолютно идеальную программу обработки естественного языка? Давайте посмотрим.
Основные проблемы natural language processing
На самом деле, с точки зрения технологии, все выглядит максимально просто и беспроблемно. Все системы обработки естественного языка работают по одному и тому же алгоритму:
- Человек задает письменные или аудиоданные.
- В случае с аудиоданными программа записывает звук и конвертирует его в текст.
- NLP-система анализирует текст, разбивая его на составляющие и пытаясь понять запрос.
- На основе полученного результата программа определяет, какие действия нужно выполнить.
Мы уже начали говорить о том, что естественный человеческий язык не так-то прост для машинного понимания. Он насыщен созвучными словами, имеющими разное значение. В естественном языке встречаются ситуации, когда одно и то же слово может иметь разное значение в зависимости от контекста.
Одно и то же действие может быть выражено разными словами-синонимами. А еще в предложении может быть спрятан скрытый подтекст, для понимания которого нужны определенный интеллект и чувство юмора. На основании всего вышеизложенного можно выделить четыре основных проблемы обработки естественного языка [Н. Осмокеску, 2019].
Проблема семантики и поиска смысла
Компьютерной программе очень легко запутаться в синонимах и омонимах, которых в большинстве европейских языков достаточно много. Так, в среде дизайнеров запросто поймут фразу «график не вписался в график», где в первом случае график – это специалист, работающий с программами графического дизайна, а во втором случае график – это план или дедлайн.
За поиск правильного смысла в программах natural language processing отвечает функция семантического анализа текста. Выявление нужного контекста обеспечивает прагматический анализ. Кроме того, обработка естественного языка ведется на морфологическом, синтаксическом, фонологическом уровнях, что ведет к неуклонному повышению качества natural language processing.
Проблема определения эмоций и тональности
Естественная речь человека всегда окрашена эмоциями. В устной речи мы используем те или иные интонации, в письменной – знаки препинания и смайлики. Программы обработки естественного языка пока не научились слышать и интерпретировать интонации, поэтому работа ведется исключительно с лексическими единицами языка.
Задача упрощается, если слова, выражающие эмоции, имеют однозначную трактовку. Например, «хорошо», «плохо», «радость», «грусть». Однако в некоторых случаях такая «предустановленная» трактовка затруднена, а то и невозможна. Особенно, если natural language processing не адаптирована под культурные традиции того или иного региона. В качестве примера можно привести интерпретацию упоминания белого цвета в тексте. В Туркменистане это цвет, приносящий удачу, а в Японии – цвет траура.
Кросс-языковая морфология и малоресурсные языки
Если сказать проще, системам обработки естественного языка легче работать с языками, имеющими четкую структуру построения предложения: английский, немецкий, французский и т.д. Несколько сложнее работать с русским языком, где, как мы говорили выше, простая перестановка слов может поменять смысл. И совсем тяжело внедрить natural language processing для малораспространенных и исчезающих языков, местных диалектов и языков, не имеющих письменности.
Тем не менее, вести работу в этом направлении нужно, потому что это может спасти многие языки от полного исчезновения, помочь учесть интересы носителей этих языков, а также спасти множество жизней в случае глобальной угрозы. Тогда мгновенный перевод с малоиспользуемого языка на все языки мира поможет быстрее распространить информацию о каком-либо бедствии и грозящей миру опасности.
Неверная корреляция
Из-за того, что язык человека богат на эмоции и скрытые смыслы, программам обработки естественного языка не всегда удается верно интерпретировать информацию. Так, человек может в ответ на какое-то плохое известие отреагировать саркастическим «Великолепно!» и сбить с толку компьютерную программу, если перед этим шла речь о том, что кто-то что-то сломал, разбил, утопил и т.д.
С другой стороны, самообучающиеся программы работают на основе той информации, которая была им задана изначально. Поэтому обретает особую важность задача правильно подготовленной обучающей выборки и подбора достаточного количества данных для адекватного самообучения. Зачем все это нужно? А вот тут мы подошли к сфере применения natural language processing.
Natural language processing: сфера применения
Конечно же, natural language processing – это не только «О’кей, гугл» в вашем смартфоне. Это обработка больших массивов данных, перевод аудио в текст, подбор контекстной рекламы и персональных рекомендаций вам в ленту новостей.
Основные сферы применения natural language processing:
- Машинный перевод.
- Проверка орфографии и грамотности текстов.
- Голосовое управление.
- Распознавание голосовых запросов.
- Показ подходящей контекстной рекламы.
- Формирование персональных рекомендаций.
- Разработка чат-ботов.
- Технологии прослушивания телефонных переговоров с целью выявления определенной информации.
- Сохранение исчезающих и малораспространенных языков.
- Анализ настроений.
На последнем пункте хотелось бы остановиться подробнее ввиду того, что он широко используется в политических технологиях. Когда-то давно для выяснения настроений избирателей были доступны лишь примитивные инструменты, такие как соцопросы и анкетирование.
Однако эти инструменты не вполне эффективны. В странах с авторитарным режимом слишком сильна спираль молчания, когда большинство людей боится высказать свое мнение из-за страха получить 15 лет тюремного заключения. И даже в демократических государствах большинство людей слишком конформны и предпочитают присоединиться к большинству с целью получения социального одобрения.
А вот в соцсетях люди чувствуют себя свободнее и более охотно делятся своим мнением, особенно под vpn и с какого-нибудь «левого» аккаунта. Технологии natural language processing позволяют выявить основные претензии к власти или кому-либо из кандидатов на выборную должность путем анализа большого массива данных из соцсетей, где люди более свободно выражают свои взгляды.
Если эти претензии выявляет власть, она получает запас времени, чтобы идентифицировать и арестовать всех недовольных. Если претензии выявляет кандидат на должность, он получает время, чтобы отреагировать и откорректировать свою предвыборную программу, имидж, позиционирование в глазах избирателей и многое другое.
Элементы natural language processing, в частности, широко использовались в президентской кампании в США в 2016 году, когда за высший пост в государстве боролись Дональд Трамп и Хиллари Клинтон. Ситуацию на предмет негативных и позитивных высказываний в адрес каждого из кандидатов мониторили каждые несколько дней:
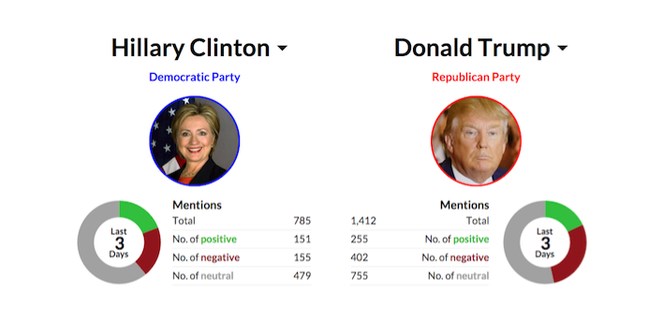
Более подробно о прикладных аспектах темы вы можете почитать в статье «Автоматическая обработка текстов: что такое Natural Language Processing» [М. Тихонова, 2022]. А у нас остается еще один важный вопрос, который наверняка уже возник у мыслящей молодежи: как научиться?
Как научиться natural language processing?
Все, что связано с искусственным интеллектом, машинным обучением и natural language processing, является весьма перспективным направлением развития. А работа в этой сфере сулит неплохие заработки, в том числе в твердой валюте, если вы хорошо владеете английским. Где можно освоить специальности, связанные с обработкой естественного языка?
Во-первых, можно найти по направлению natural language processing курсы. В зависимости от специализации они могут стоить от 42 до 95 тысяч рублей и длиться от 2,5 до 13 месяцев [Р. Дулева, 2021]. Во-вторых, в этом помогут книги. Расскажем о некоторых из них.
Для начинающих подойдет издание Natural Language Processing with Python [S. Bird, E. Klein, E. Loper, 2009]. Материал изложен очень доступным языком. Прочитав книгу, вы сможете освоить разные технологии, от фильтрации электронной почты до автоматического суммирования и перевода. С помощью этой книги вы научитесь писать программы на Python с использованием библиотеки с открытым исходным кодом Natural Language Toolkit (NLTK). А также научитесь:
- Извлекать информацию из неструктурированного текста, чтобы «угадать» тему.
- Анализировать языковую структуру в тексте, включая синтаксический и семантический анализ.
- Интегрировать методы, взятые из таких разных областей, как лингвистика и искусственный интеллект.
Кроме того, читателям обещан доступ к популярным лингвистическим базам данных, включая WordNet и treebanks. Можно скачать книгу по natural language processing в pdf по ссылке.
Весьма интересна книга Natural Language Processing with Transformers: Building Language Applications with Hugging Face [L. Tunstall, L. Werra, T. Wolf, 2022]. Дело в том, что с момента своего появления трансформеры быстро стали доминирующей архитектурой для достижения самых современных результатов в различных задачах обработки естественного языка.
Трансформеры используются, в частности, для генерации новостей на основе заданной информации, улучшения обработки поисковых запросов Google и даже для создания чат-ботов, которые могут пошутить с собеседником. Если вы специалист по данным или кодер, эта книга покажет вам на практике, как обучать и масштабировать большие модели с помощью Hugging Face Transformers.
И, наконец, книга Transfer Learning for Natural Language Processing [P. Azunre, 2021]. Эта книга научит вас создавать собственные модели NLP в рекордно короткие сроки, адаптируя предварительно обученные модели для решения специализированных задач. В издании рассматриваются такие темы, как точная настройка предварительно обученных моделей с новыми данными предметной области, выбор правильной модели для сокращения использования ресурсов, генерация текста с помощью предварительно обученных преобразователей языка. Книга предназначена для инженеров по машинному обучению и специалистов по данным, имеющих некоторый опыт работы с NLP.
Если вам что-то из перечисленного кажется слишком сложным, пройдите нашу программу «Когнитивистика». Вы прокачаете свое мышление настолько, что неподъемных для вашего интеллекта задач не останется в принципе. Кроме того, вам будет полезно изучить дополнительную литературу по теме искусственного интеллекта. Например, монографию «Системы представления знаний» [Ф. Новиков, 2010]. А еще вам поможет позитивный настрой и искренний интерес к новым знаниям.
Мы желаем, чтобы вы всегда сохраняли позитивное отношение к жизни и здоровую любознательность. И просим вас ответить на вопрос по теме статьи: