
Урок 2. Как работает машинное обучение
 Машинное обучение – это методология искусственного интеллекта, которая позволяет компьютерным системам учиться на основе опыта без активного программирования. В этом уроке мы рассмотрим основные концепции машинного обучения, включая типы задач, алгоритмы и инструменты, используемые для создания моделей машинного обучения.
Машинное обучение – это методология искусственного интеллекта, которая позволяет компьютерным системам учиться на основе опыта без активного программирования. В этом уроке мы рассмотрим основные концепции машинного обучения, включая типы задач, алгоритмы и инструменты, используемые для создания моделей машинного обучения.
Также мы рассмотрим, как машинное обучение используется в различных отраслях, таких как медицина, финансы и технологии.
Содержание:
- Что такое машинное обучение?
- Основные типы задач машинного обучения
- Основные алгоритмы машинного обучения
- Обучающая и тестовая выборки
- Задание на взаимопроверку
- Примеры использования машинного обучения
- Проверочный тест
Как и следует полагать, урок мы начнем с небольшого разговора о машинном обучении как таковом.
Что такое машинное обучение?
Машинное обучение, как мы и сказали в начале, это методология искусственного интеллекта, которая позволяет компьютерным системам учиться на основе опыта без активного программирования. Эта технология используется для создания компьютерных систем, которые могут обучаться и сами улучшать свою производительность при выполнении задач, которые ранее требовали человеческого участия или были сложными для прямого программирования.
Машинное обучение используется в различных отраслях, таких как медицина, финансы, технологии, реклама и другие. В медицине, например, машинное обучение может использоваться для диагностики и прогнозирования различных заболеваний. В финансовой отрасли машинное обучение помогает в принятии решений по кредитованию, определению инвестиционных стратегий и т.д. Обо всем этом мы и поговорим далее.
Основные типы задач машинного обучения
Основные типы задач машинного обучения включают классификацию, регрессию, кластеризацию и обработку естественного языка.
Классификация
Классификация является одним из самых распространенных типов задач машинного обучения. Она заключается в отнесении объектов к определенным категориям или классам. Например, можно использовать классификацию для определения того, является ли электронное письмо спамом. В этом случае модель обучается на основе примеров уже размеченных писем и в дальнейшем может автоматически определять, относить письмо к спаму или нет.
Регрессия
Регрессия является типом задачи машинного обучения, которая предсказывает числовые значения на основе данных. Например, можно использовать регрессию для определения цены на недвижимость на основе ее характеристик, таких как количество комнат, площадь, местоположение и т.д. В этом случае модель обучается на основе примеров, содержащих информацию о проданных объектах, и в дальнейшем может автоматически предсказывать цену на новые объекты.
Кластеризация
Кластеризация – это тип задачи машинного обучения, который позволяет группировать объекты на основе сходства между ними. Кластеризацию можно использовать, к примеру, для определения групп покупателей, имеющих схожие предпочтения при покупке товаров. В этом случае модель обучается на основе информации о покупках и в дальнейшем может автоматически группировать покупателей со схожими интересами.
Обработка естественного языка
Обработка естественного языка представляет собой тип задачи машинного обучения, который позволяет анализировать текстовые данные и извлекать из них значимую информацию. Так, можно использовать обработку естественного языка для определения тональности отзывов о продукте, написанных пользователями. В этом случае модель обучается на основе текстов отзывов, а после автоматически определяет, положительный или отрицательный отзыв написал пользователь.
Каждый из этих типов задач машинного обучения имеет свои специфические алгоритмы и подходы для обучения моделей, о которых непременно следует сказать детальнее.
Основные алгоритмы машинного обучения
Знание основных алгоритмов машинного обучения является важным для любого, кто занимается анализом данных и разработкой моделей машинного обучения. Понимание принципов работы и применения каждого алгоритма позволит выбрать подходящий алгоритм для решения конкретной задачи и оптимизировать процесс обучения моделей.
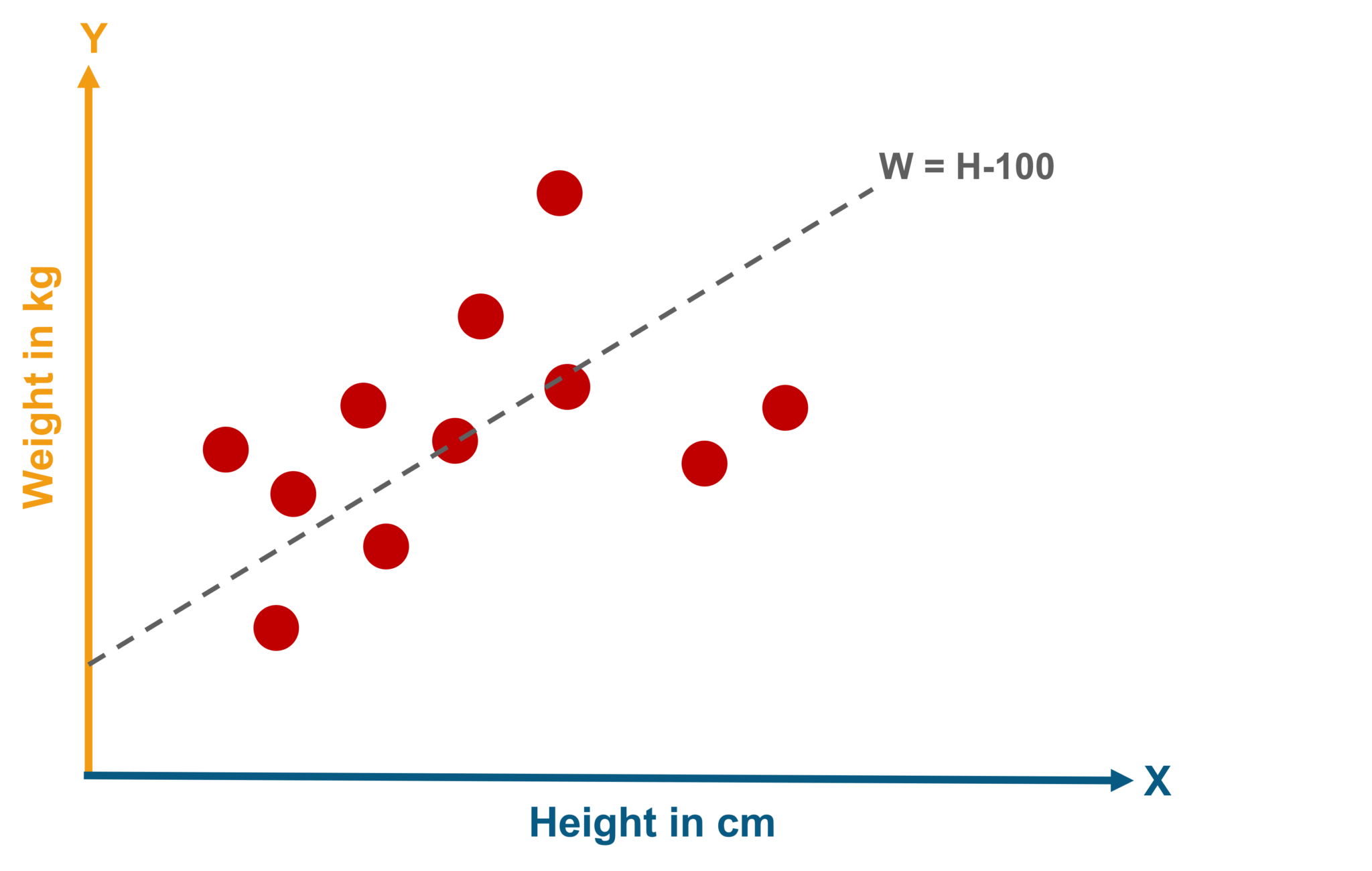
Линейная регрессия
Линейная регрессия – это алгоритм, который используется для построения модели регрессии. Линейная регрессия предсказывает значения зависимой переменной на основе линейной комбинации нескольких независимых переменных. Этот алгоритм подходит для прогнозирования числовых значений.
Визуально линейную регрессию можно представить так:
Логистическая регрессия
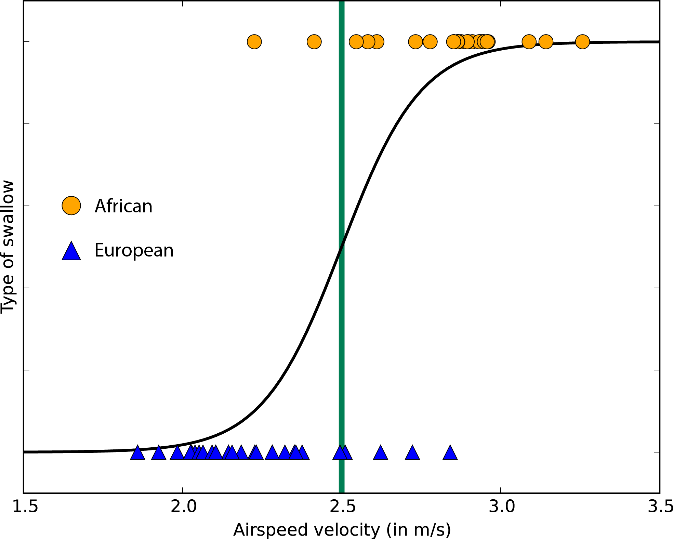
Логистическая регрессия – это алгоритм, который используется для классификации объектов. Логистическая регрессия прогнозирует вероятность принадлежности объекта к определенному классу. Этот алгоритм обычно используется для бинарной классификации, т.е. когда объекты относятся только к двум классам.
Визуально логистическую регрессию можно представить так:
Деревья решений
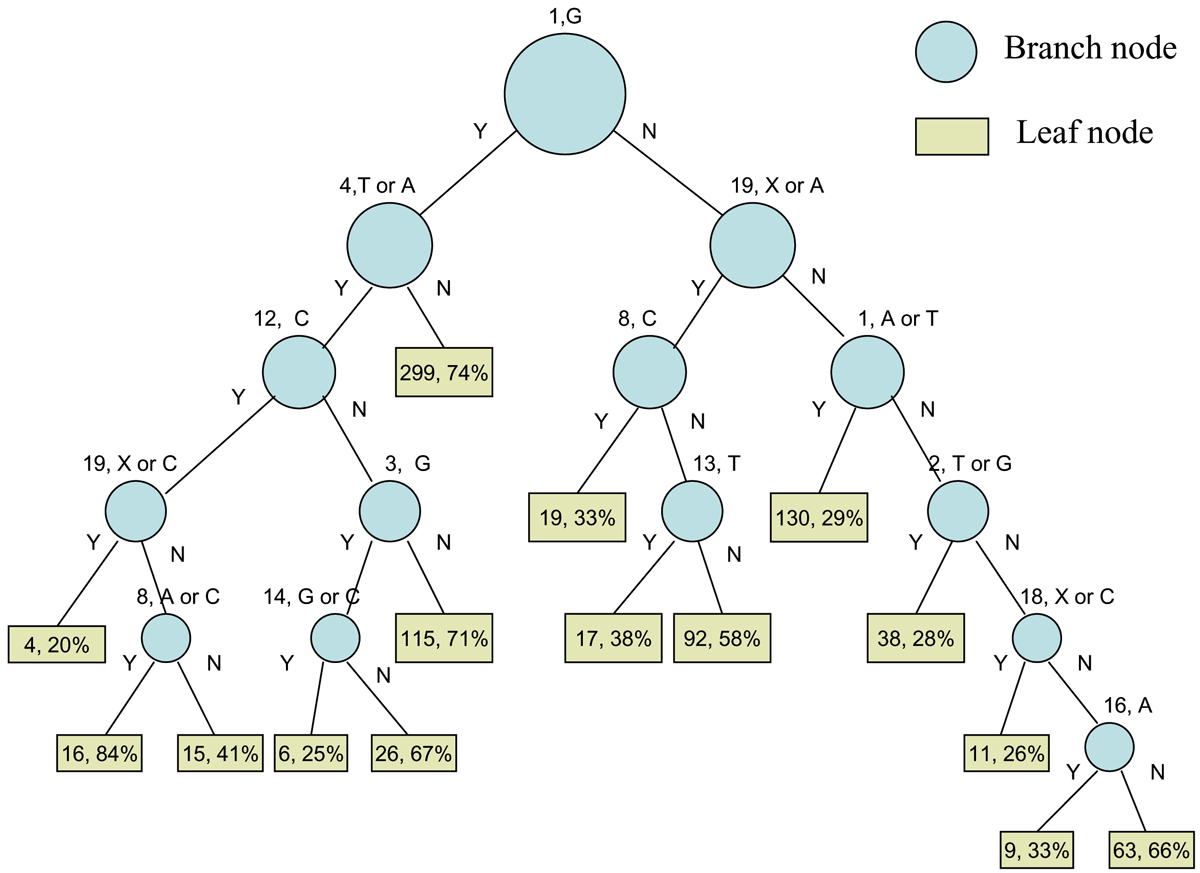
Деревья решений – это алгоритм, применяемый для решения задач классификации и регрессии. Деревья решений представляют собой древовидную структуру, где каждый узел соответствует некоторому условию на входных данных, а каждый лист дерева соответствует предсказанию для объектов, которые соответствуют данному пути от корня до листа.
Ниже вы можете посмотреть на пример дерева решений:
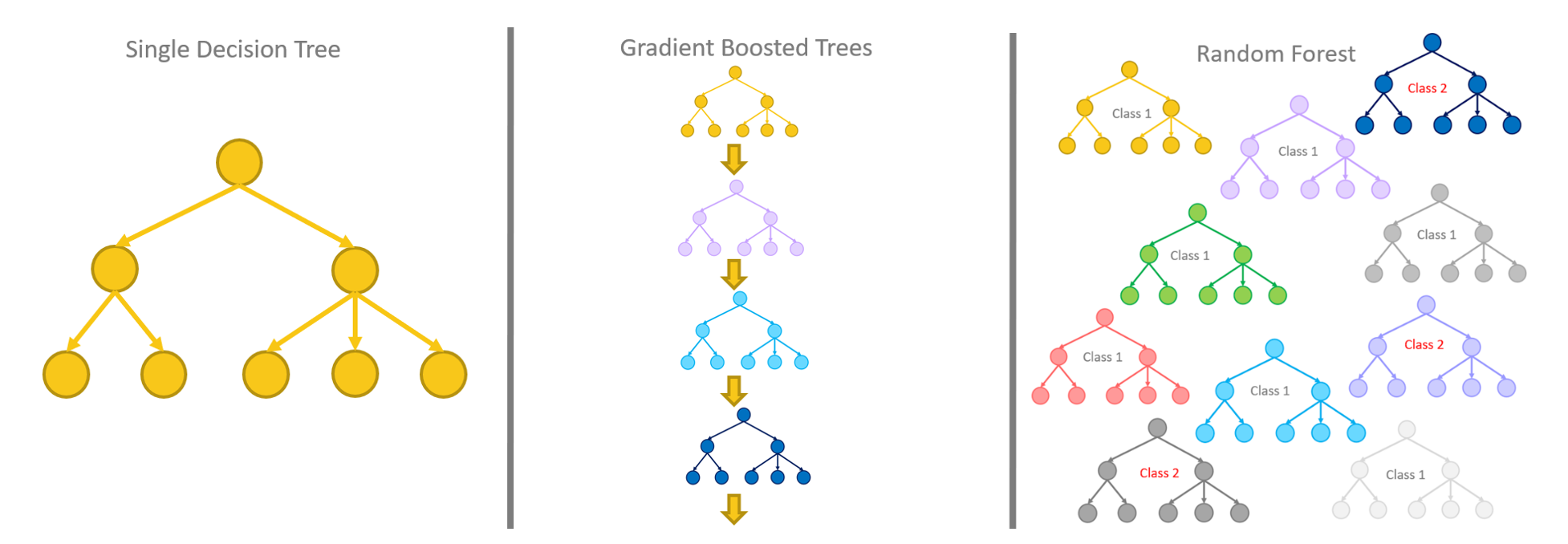
Случайный лес
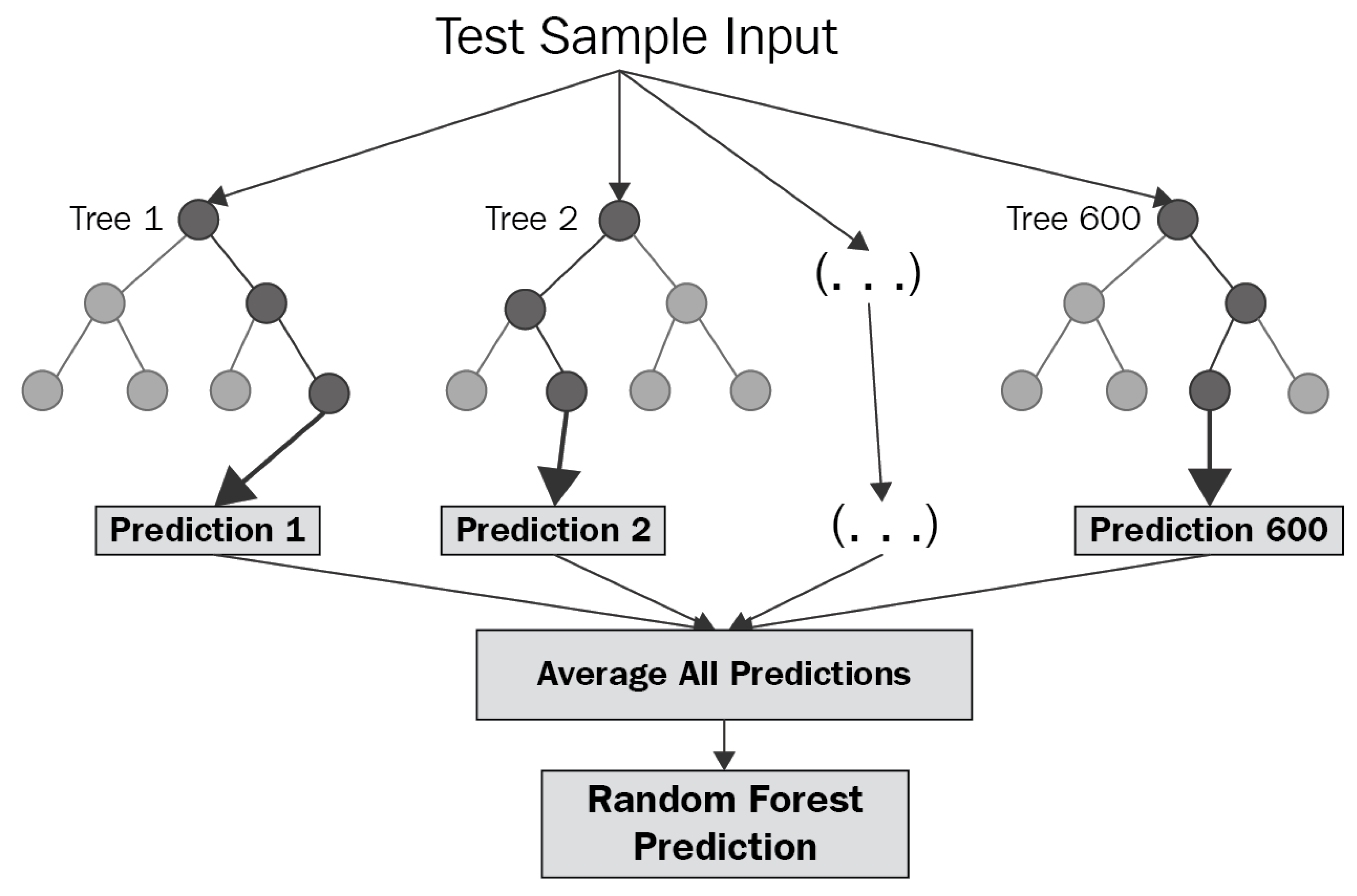
Случайный лес – это алгоритм, который используется для классификации и регрессии. Случайный лес представляет собой ансамбль деревьев решений, где каждое дерево обучается на случайной выборке данных и случайном наборе признаков. Затем предсказание производится путем агрегирования предсказаний всех деревьев.
Вот пример случайного леса:
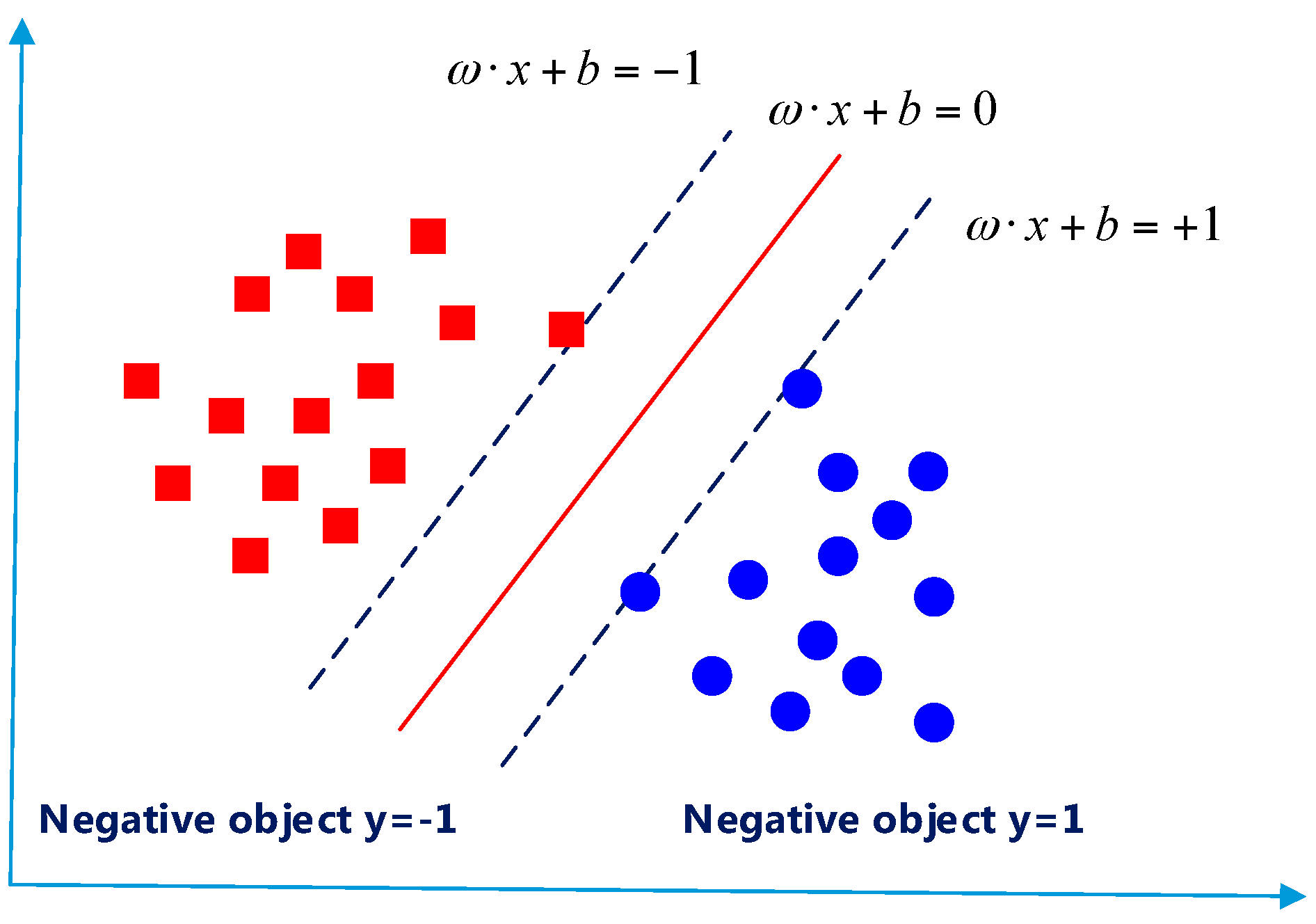
Метод опорных векторов (SVM)
Метод опорных векторов – это алгоритм, применяемый для решения задач классификации и регрессии. SVM ищет гиперплоскость, которая лучше всего разделяет объекты разных классов в пространстве признаков. SVM также может использоваться для решения задачи поиска аномалий (англ. anomaly detection).
Визуально SVM можно представить так:
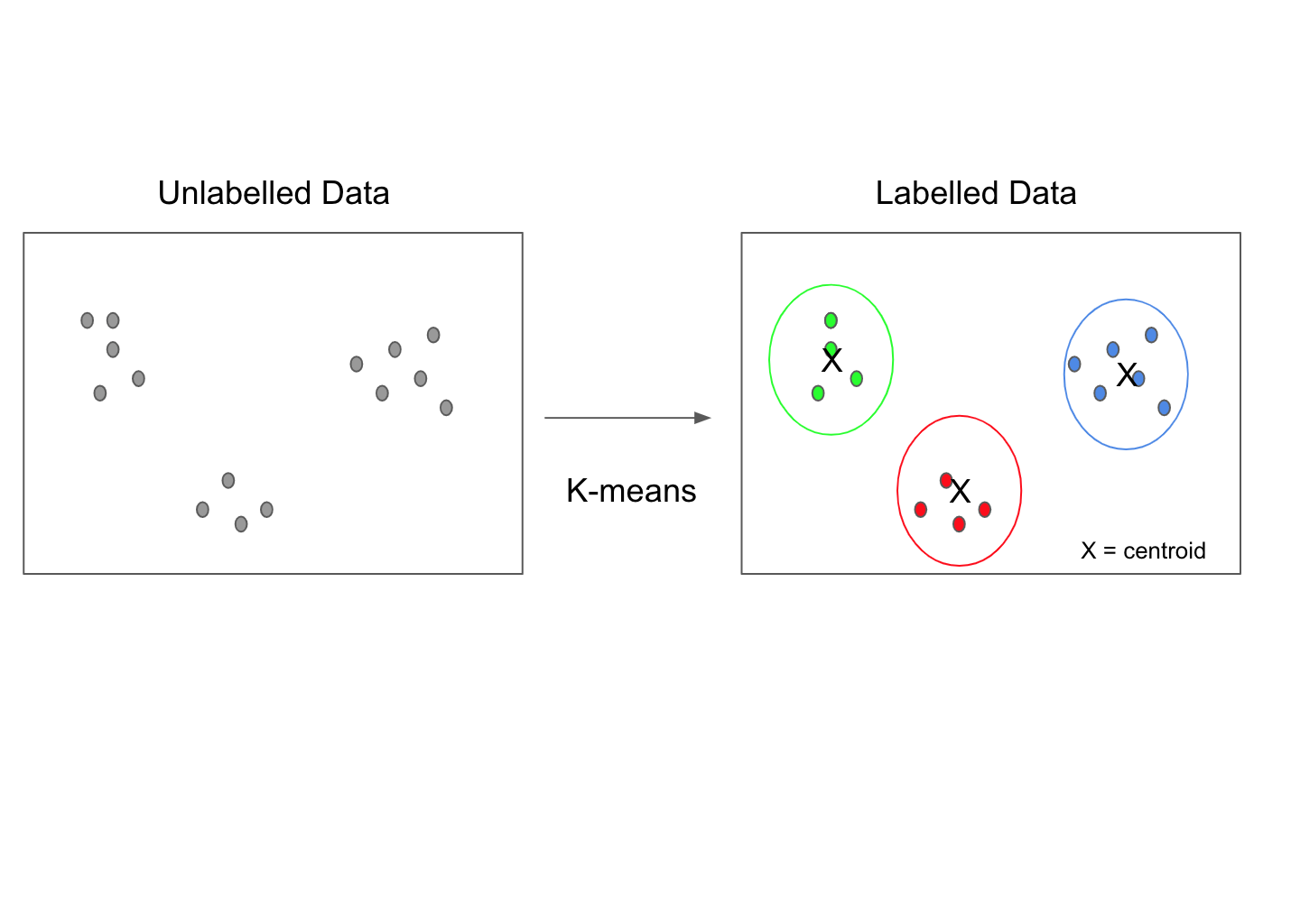
К-средних
K-средних – это алгоритм, который используется для кластеризации данных. K-средних разделяет данные на кластеры, где каждый кластер представляет группу объектов, которые находятся близко друг к другу в пространстве признаков. Количество кластеров определяется заранее.
Визуально это выглядит следующим образом:
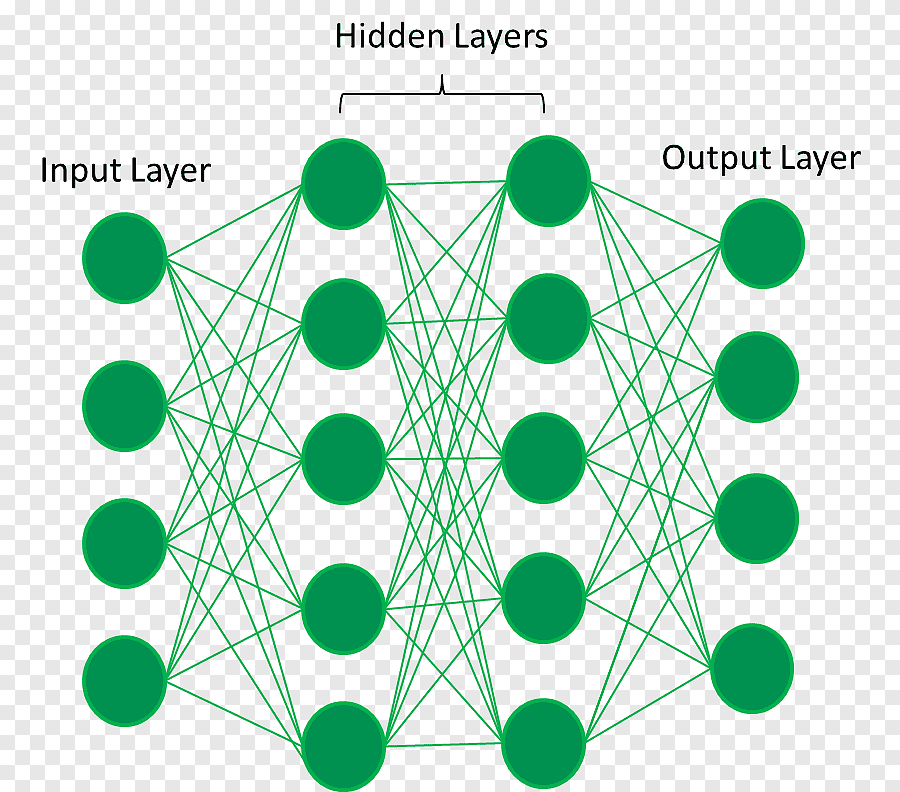
Нейронные сети
Нейронные сети – это алгоритм, который используется для решения различных задач, включая классификацию, регрессию, обработку естественного языка и многие другие. Нейронные сети – это модель, имитирующая работу человеческого мозга и состоящая из большого количества взаимосвязанных нейронов. Нейронные сети обучаются на большом количестве данных, где каждый нейрон находит определенные закономерности в них.
Вот пример нейронной сети:
Градиентный бустинг
Градиентный бустинг – это алгоритм, который используется для решения задач регрессии и классификации. По сути, это ансамбль моделей, где каждая последующая модель обучается на ошибках предыдущей модели. Это позволяет улучшать точность предсказаний с каждой новой моделью.
Пример градиентного бустинга вы можете увидеть ниже:
Ассоциативные правила
Ассоциативные правила – это алгоритм, который используется для анализа ассоциативных связей между переменными. Ассоциативные правила могут помочь в выявлении скрытых зависимостей между переменными и выявлении интересных факторов в данных.
Визуально это выглядит примерно так:
Кроме того, существуют и другие алгоритмы машинного обучения, такие как наивный Байес, машина опорных векторов с ядром (SVM с ядром), метод k-ближайших соседей (k-NN) и другие. Каждый из этих алгоритмов имеет свои особенности и применяется для решения определенных задач в различных отраслях.
Но не менее важным для успешного машинного обучения является понимание того, что такое обучающая выборка и тестовая выборка. Почему это так, мы расскажем далее.
Обучающая и тестовая выборки
Понимание того, что такое обучающая выборка и тестовая выборка, является критически важным для успешного обучения моделей машинного обучения и получения точных предсказаний:
| | Обучающая выборка представляет собой набор данных, на которых модель обучается, т.е. на основе которых она настраивает свои веса и определяет зависимости между входными данными и целевой переменной. |
| | Тестовая выборка, с другой стороны, представляет собой независимый набор данных, на которых модель не обучалась, но который используется для оценки ее качества и точности предсказаний. |
Разделение данных на обучающую и тестовую выборки необходимо для оценки способности модели к обобщению на новых данных, которых не было в обучающей выборке. Если модель будет обучена на данных из обучающей выборки и затем протестирована на тех же данных, она может показать высокую точность предсказаний, но при этом плохо справляться с новыми данными. Это явление называется переобучением (overfitting) и приводит к тому, что модель не может применяться к реальным задачам, где данные могут быть разнообразными.
Чтобы избежать переобучения и проверить способность модели к обобщению, необходимо использовать тестовую выборку для проверки точности предсказаний на новых данных. Тестовая выборка должна быть представительной для всего набора данных, но не должна пересекаться с обучающей выборкой.
Вместе с тем, особенно важно использовать еще и кросс-валидацию, метод, который позволяет оценить точность и устойчивость модели машинного обучения путем разбиения данных на несколько частей и последовательного использования каждой из них как тестовой выборки. Это позволяет избежать проблемы переобучения модели на обучающей выборке и дает более объективную оценку качества модели на независимых данных.
В основе кросс-валидации лежит идея разделения данных на несколько складок (folds), обучения модели на нескольких складках и использования оставшейся части данных для тестирования модели. Процедура повторяется несколько раз с разными комбинациями складок, и в итоге получается оценка точности модели на всем наборе данных.
Кросс-валидация позволяет оценить точность модели на независимых данных и сравнить качество разных моделей на одних и тех же данных. Этот метод также помогает снизить влияние случайных факторов, таких как разбиение на обучающую и тестовую выборки, и улучшить устойчивость модели.
Зная, что такое обучающая и тестовая выборки, а также умея проводить кросс-валидацию, специалисты могут успешно обучать модели машинного обучения и получать точные предсказания, а значит, и применять полученные результаты к реальным задачам. И в следующем разделе мы рассмотрим некоторые примеры применения машинного обучения в различных областях, чтобы продемонстрировать значение всего сказанного выше.
Задание на взаимную проверку
Прежде чем мы рассмотрим примеры применения машинного обучения в различных областях, предлагаем вам самим немного поразмышлять на эту тему.
Выберите любую интересную вам область (наука, техника, здравоохранение, транспорт и т.д.) и предложите, как и для чего можно было бы использовать в ней машинное обучение, какую конкретно технологию вы хотели бы внедрить. Дайте подробные пояснения: для чего она будет использоваться, какую функцию выполнять, как сможет улучшить жизнь человека.
Объем текста должен составлять не более 300 слов. Это задание на взаимную проверку, поэтому сначала вам нужно проверить две работы других пользователей, а затем загрузить свою. При проверке чужих работ вам необходимо оценить оригинальность идеи, степень ее полезности для человека и возможность реализации.
Примеры использования машинного обучения
Машинное обучение является важной областью в информационных технологиях и науке о данных. Как уже стало понятно, эта технология использует различные алгоритмы и модели, чтобы на основе данных обучить компьютерные системы делать прогнозы, принимать решения и выполнять задачи.
И вот где может пригодиться машинное обучение:
- Классификация изображений. Машинное обучение может использоваться для распознавания объектов на изображениях, например, в медицине для обнаружения рака на рентгеновских снимках.
- Анализ текста. Машинное обучение может использоваться для автоматической обработки и анализа больших объемов текстовой информации, например, в социальных сетях для анализа настроений пользователей.
- Прогнозирование временных рядов. Машинное обучение может использоваться, например, для прогнозирования продаж или изменения цен на фондовом рынке.
- Определение обмана и мошенничества. Машинное обучение может использоваться в банковской сфере для обнаружения незаконных операций с кредитными картами.
- Рекомендательные системы. Машинное обучение может использоваться для создания персонализированных рекомендаций, к примеру, для рекомендации фильмов или товаров в интернет-магазинах.
- Обработка естественного языка. Машинное обучение может использоваться для автоматического перевода текстов на разные языки.
- Автопилоты для автомобилей. Машинное обучение может использоваться для разработки систем автоматического управления электромобилями, которые способны определять препятствия на дороге и принимать решения о маршруте и скорости движения.
- Обработка звука. Машинное обучение может использоваться для распознавания речи или музыкальных инструментов.
- Оптимизация процессов. Машинное обучение может использоваться для оптимизации процессов в промышленности, например, в производстве или управлении качеством продукции.
- Определение болезней. Машинное обучение может использоваться для обработки медицинских данных и определения болезней, например, для диагностики рака или диабета.
Машинное обучение имеет огромное значение в нашей жизни, поскольку позволяет нам делать более точные прогнозы, принимать решения на основе больших объемов данных, создавать персонализированные рекомендации, оптимизировать процессы и многое другое.
Благодаря машинному обучению мы можем улучшать качество жизни, повышать эффективность процессов и создавать новые возможности для роста и развития в различных сферах деятельности.
И одним из ключевых аспектов машинного обучения является правильная обработка данных, поскольку качество обучения и точность моделей зависят от качества данных, на которых они обучаются. И об этом мы подробно поговорим на следующем уроке, а пока предлагаем закрепить полученные знания с помощью небольшого проверочного теста.
Проверьте свои знания
Если вы хотите проверить свои знания по теме данного урока, можете пройти небольшой тест, состоящий из нескольких вопросов. В каждом вопросе правильным может быть только один вариант. После выбора вами одного из вариантов система автоматически переходит к следующему вопросу. На получаемые вами баллы влияет правильность ваших ответов и затраченное на прохождение время. Обратите внимание, что вопросы каждый раз разные, а варианты перемешиваются.
Переходим к обработке данных для машинного обучения.
 Дмитрий Гераськин
Дмитрий Гераськин Кирилл Ногалес
Кирилл Ногалес